(Actually it doesn't matter about the version of WSS 3.0 (whether or sp1 is applied), what matters is the pdf ifilter. )
You may have installed WSS 3.0 on a server or two and had no problems with Search. It works great, indexing content on a tidy schedule with no mishaps-- users can search for anything in a site collection, from announcements to the contents of big Word documents. But, when the users try to get fancy and introduce PDFs to the mix, things get tricky because WSS doesn't search the content of those.
You see, WSS 3.0 can search standard Windows File types (meaning Office file types and text files mostly). Supposedly it can also, out of the box, identify characters in OCR'd TIF files. However, it cannot search PDF files.
Why? Because MS only offers index filter files (files that teach the WSS indexing service how to gather data ) for their file types.
However, you could get an index filter file (called an ifilter) by downloading it from adobe if you wanted to be able to index PDF file contents.
And that worked for versions 5 and 6, but when version 8.0 came out, things changed. You see, you used to be able to download the older ifilters straight from Adobe, but suddenly, you can't for version 8.0.
Why? Because the ifilter file is now bundled with Adobe Reader. So to get the ifilter, you have to install Adobe Reader (8.0 or higher) onto the WSS server that will be doing indexing.
However, not a lot of people know that. Which is why there are people in the public newsgroups having problems indexing their pdf files in WSS 3.0 (or higher). So either people don't realize that they need a pdf related ifilter or people do download and use the older Adobe PDF ifilter files, thinking that'll do it.
But people who download the older ifilters find they can only index PDF files of that version and lower, not non-adobe pdfs or higher versions. To index older version, non-pdf, and newest versions of PDF, you need the newest version of the ifilter (currently 8.1.1)
Of course, a company called FoxIt capitalized on people's confusion about getting and using ifilters by offering their PDF IFilter-- for a pretty penny of course.
But Adobe is still offering their ifilter for free. The only price you pay is having to install Adobe Reader on the server. And if that is too steep, then, well, it's good to know now before going any further.
There are a few tricks to getting the ifilter to work with WSS. Basically WSS needs to know it's there and what extension to use it on, so a few registry changes are in order.
Namely you will have to edit the registry to add the PDF file type to the Extensions List for WSS search, and to map the extension to a particular ifilter.
To do that go to regedit (go to Start Menu>Run> type regedit, hit Enter). Once in the registry, open the key:
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Shared Tools\Web Server Extensions\12.0\Search\Applications\{ANYGUID}\Gather\Search\Extensions\ExtensionList
The extension list is full of all the extensions that the indexing service (the Gatherer as it were) should recognize, listed as the string values of consecutive numbers, containing value data that indicates the extension.
To add PDF to the list, you simply find the highest number in the list (it goes in order, 1,2, 3, 4... up to the last of them), add a String Value that is the next higher value (so if the highest value was 37 for example, the string value you would add is 38), and enter "pdf" for the Value Data.
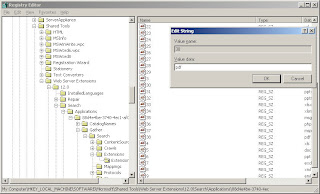
Then go to the next key:
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Shared Tools\Web Server Extensions\12.0\Search\Setup\ContentIndexCommon\Filters\Extension
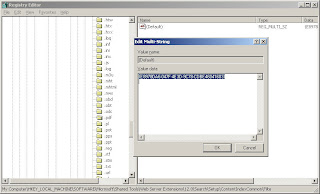
Here should be listed the file extensions with a CLSID (class ID) for the ifilter used to index the extension. If .pdf is not listed, add it (it should have a multi string value). In that multi-string value, you need to add the CLSID for the ifilter added by Adobe Reader. This file is called, for version 8.1.1. "AcroRDIF.dll." You can look up it's CLSID by doing a Find under the CLSID key (under HKEY_CLASSES_ROOT).
[[ Edited to add-- the CLSID that you are looking for to do filtering is under HKEY_CLASSES_ROOT\CLSID\ --I mention this because there are other CLSIDs that relate to other functions for acrobat in the registry. The one we need has the Reg SZ value of "PDF Filter".]]
Or, because, conveniently, the CLSID is posted on the web in several places because it is the same for version 8.1.1. as it is for the 8.0 version of Adobe Reader, you can just type it in:
{E8978DA6-047F-4E3D-9C78-CDBE46041603}
Mind you, if you are using a different, newer version, this CLSID may not work and therefore you'll need to find out the ifilter file name for your version and then search for it in the CLSID key in the registry. I find using the true filesystem path and the file name is better than just using the file name, sometimes the dll can be listed in a few places. You may need to experiment.
Anyway, I digress-- Once you've either found or added the .pdf key, enter the CLSID for the value (be sure to include the fancy brackets).
To let the server know where the Adobe Reader executable and its associated files are, add its path to the evironment variables of the server.
(Start Menu>right click My Computer>select Properties>go to the Advanced tab>click on the Environmental Variables button and scroll down the Path variable>select it and click on the Edit button> and add the path ";C:\Program Files\Adobe\Reader 8.0\Reader" (be sure to use the correct version if you are using something newer than 8.x)>then click OK to apply and close)
Finally, to let WSS know that it needs to index PDF files now, you can do one of two things:
1) reboot the server (seems to always work, but may not be possible in your environment). Instinctively, I guess because I am old school, I reboot when making changes to the registry.
OR
2) First stop and restart the Windows SharePoint Search Service (at the command prompt, use "net stop spsearch" then "net start spssearch." And then force the index service (if you don't want to wait for it to index on its preset schedule) to do a fullcrawl by, using STSADM:
stsadm -o spsearch -action fullcrawlstop
(again that's a bit of instinct there, I am figuring if it happens to be in the middle of a crawl I want it to stop and start over using the new ifilter)
stsadm -o spsearch -action fullcrawlstart
Remember that the stsadm command is in the C:\Program Files\Common Files\Microsoft Shared\web server extensions\12\BIN folder (if it isn't already set as a an enviromental path variable).
Regardless of which you choose, it may take some time for the pdf files to be indexed properly. I have found the second option to not be as guaranteed to work as simply rebooting and waiting for it to index on its own. But, no matter how long it initially takes, I found this free and relatively easy solution to indexing PDF files with WSS 3.0 to work, every time.